How I Scaled a Database from 100 Users to 100K+ Requests per Day

Habib Qureshi
MVP Developer
4 min read
Mar 19, 2026
Most system design advice jumps straight to microservices, sharding, and distributed systems. But that's not how real systems grow. In production, complexity is earned, not designed upfront. Having scaled applications from a handful of users to 100K+ daily requests, the biggest lesson is this: don't build for scale on day one. Grow into it.
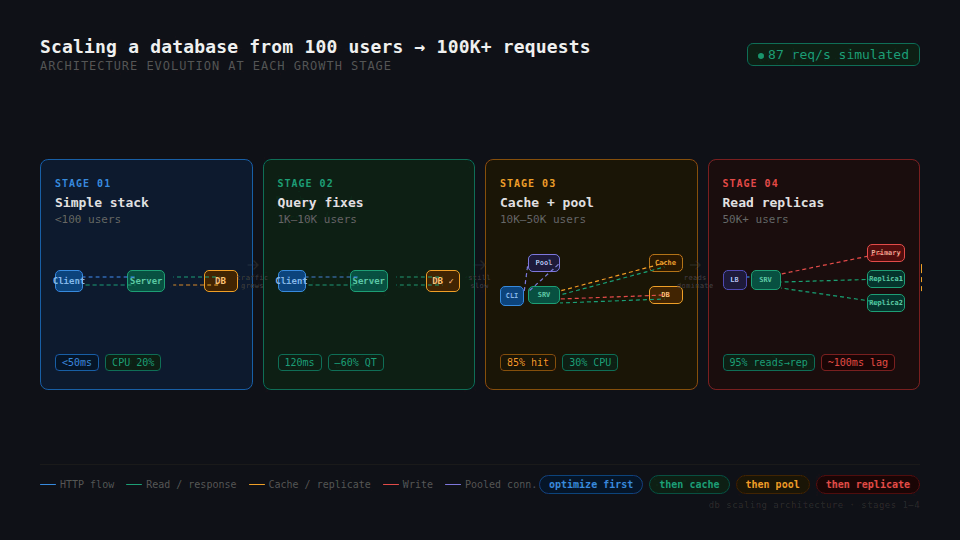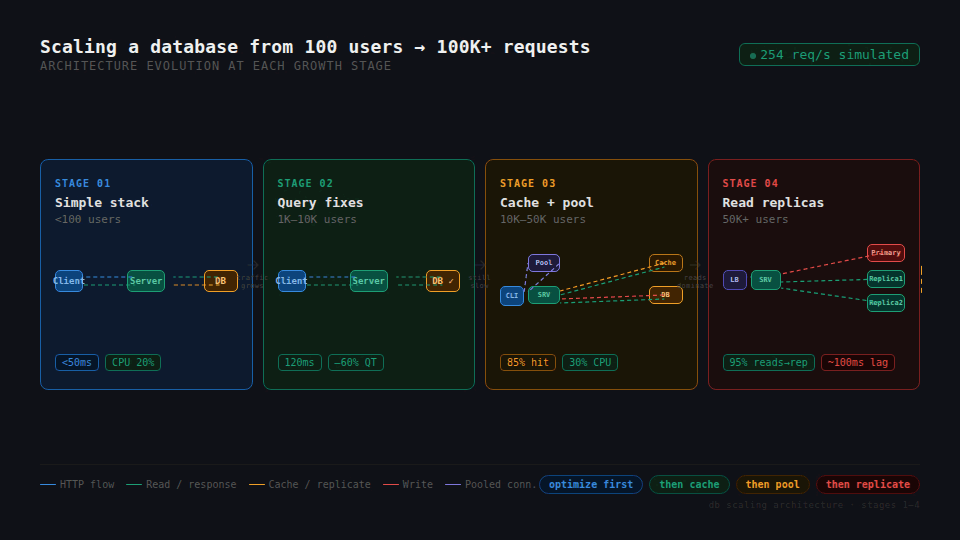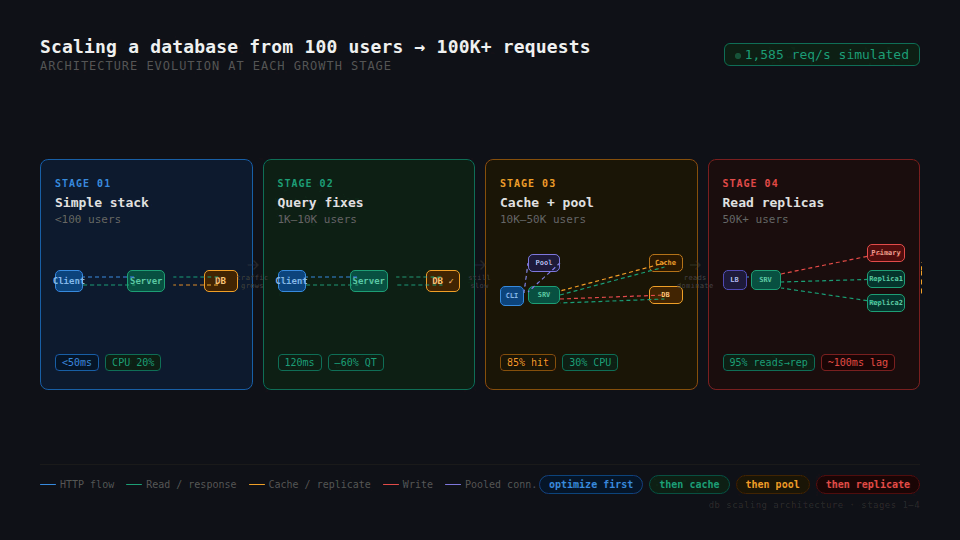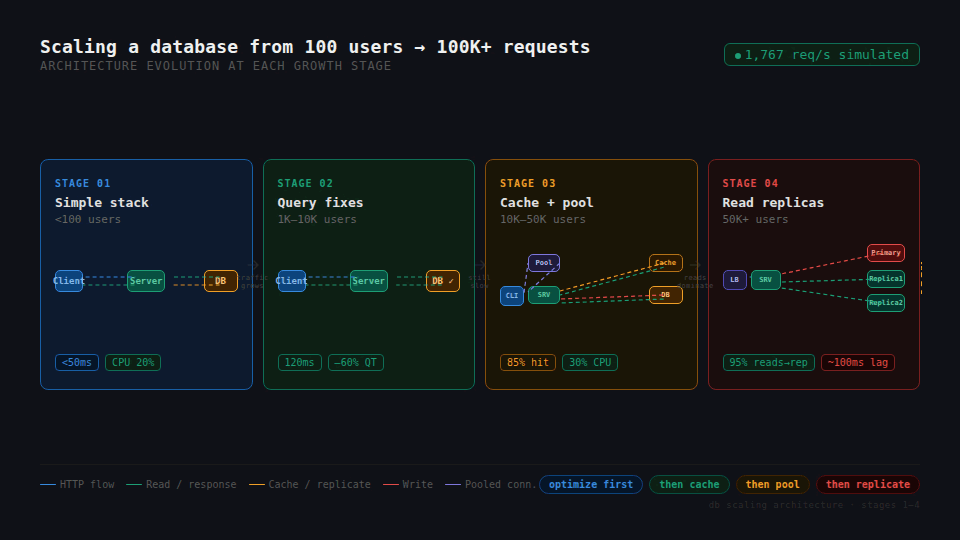
Stage 1: The comfortable start < 100 users
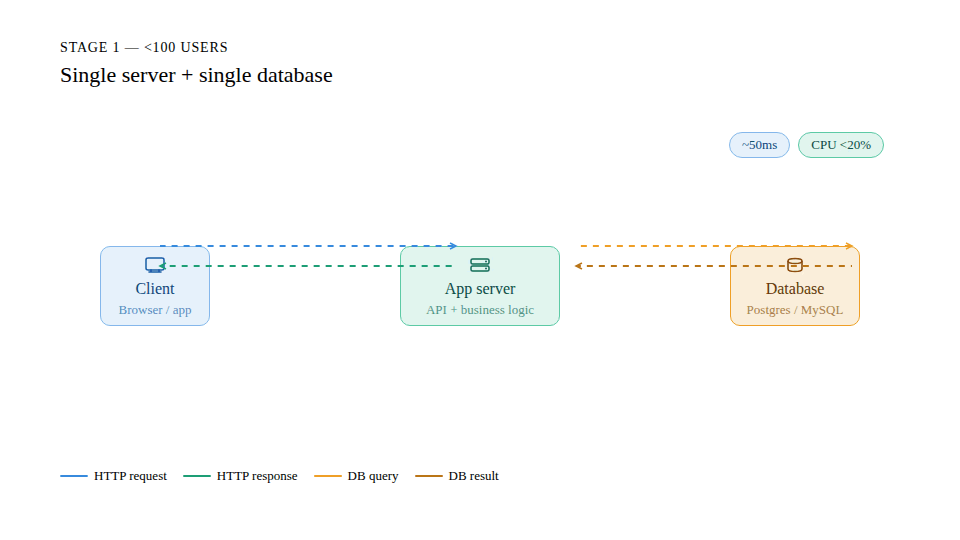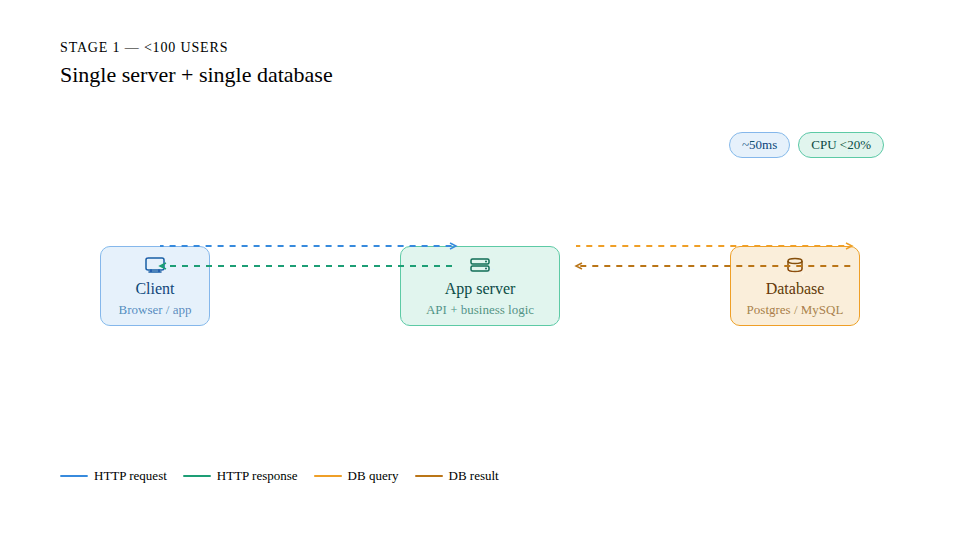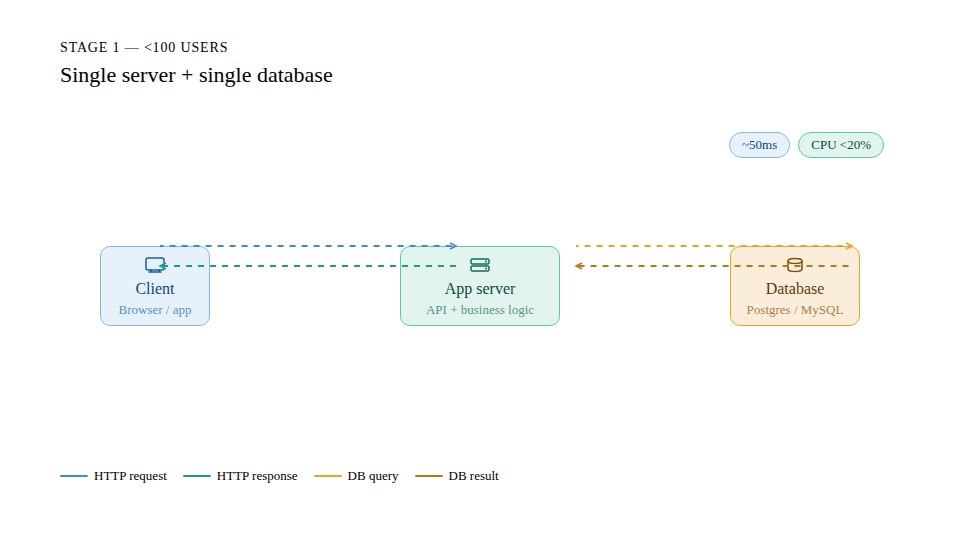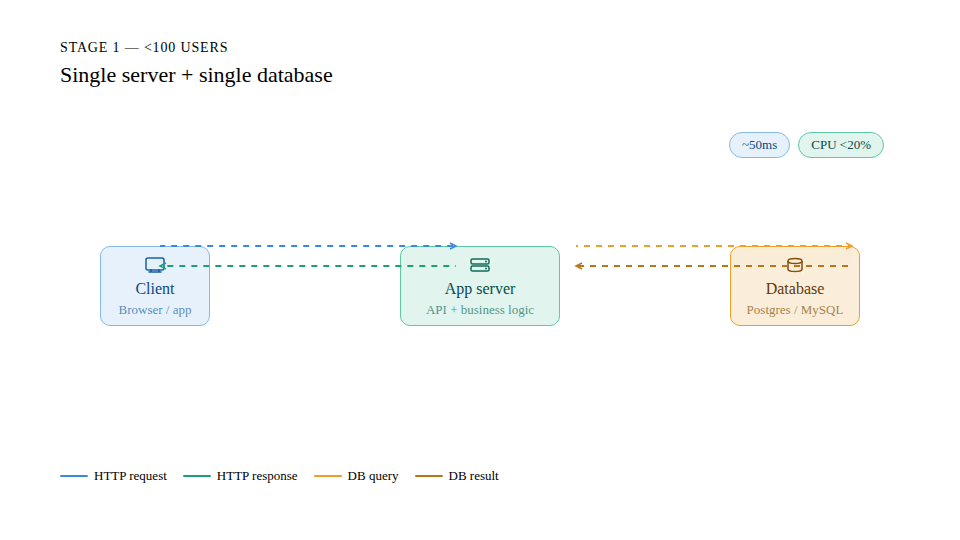
In the early stage, everything is fast and simple. Queries return in under 50ms, CPU usage stays low, and a single database instance handles everything with ease. There's no need for caching, replicas, or advanced architecture. The priority here is not scalability, it's speed of execution. Ship fast, validate the product. Designing for millions of users at this stage only increases cost and slows you down.
Stage 2: Growth begins when things start to break ~1K–10K users

As traffic increases, cracks appear. API response times climb from ~100ms to 700ms during peak hours, and database CPU usage sits above 70% consistently. Many developers instinctively jump to scaling infrastructure here — but the real culprit is usually inefficient queries. Analyzing slow query logs and execution plans typically reveals a familiar set of problems:
- Unnecessary SELECT * fetching far more data than needed
- Missing indexes on frequently filtered columns
- Inefficient joins on growing tables
Fixing these reduced query times by over 60% and stabilized the system no infrastructure changes required. At this stage, most performance problems aren't caused by scale. They're caused by how the database is being used.
Stage 3: Concurrency becomes the problem ~10K–50K users
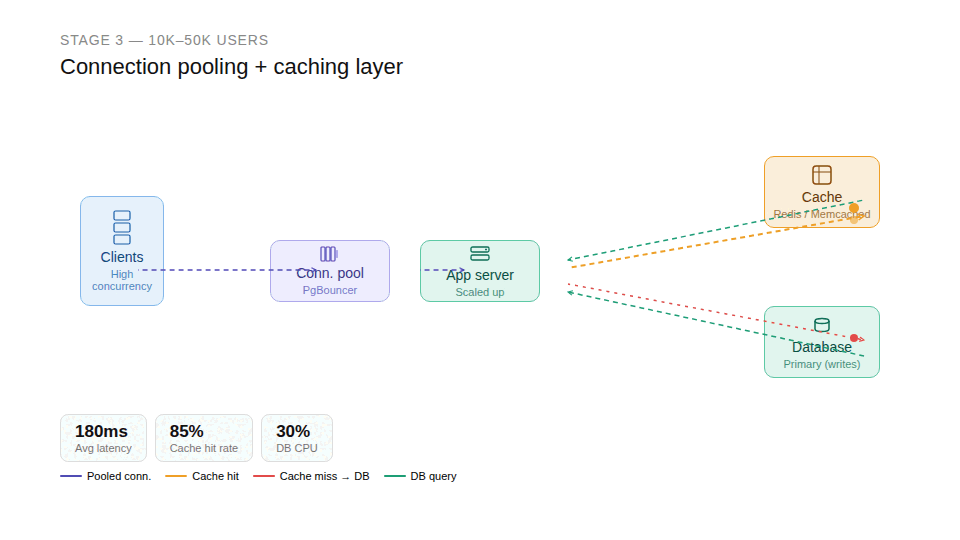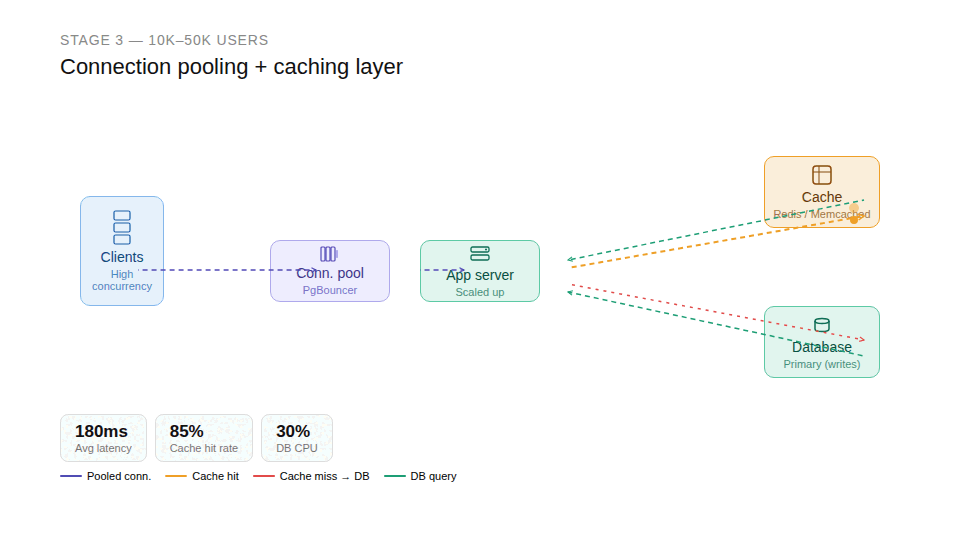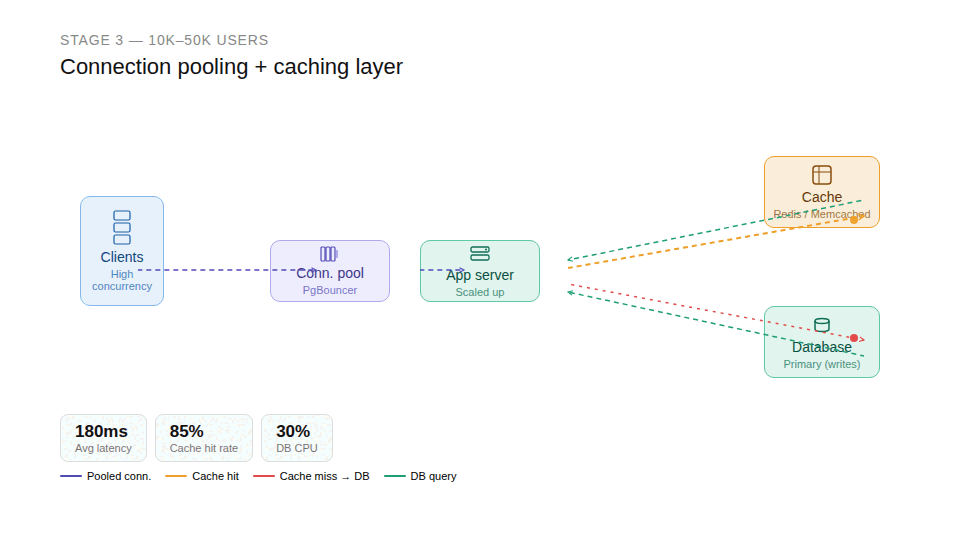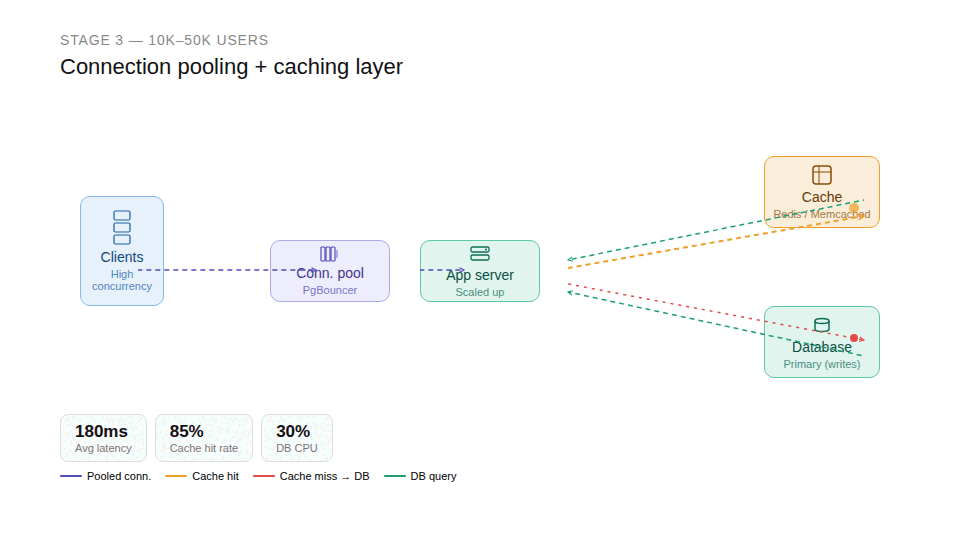
Even well-optimized queries have limits. With enough concurrent users, connection counts spike and timeouts start appearing. This is when infrastructure changes become unavoidable. Three interventions matter most at this stage:
- Connection pooling prevents the database from being overwhelmed by raw connection counts, tools like PgBouncer sit in front of the database and multiplex connections efficiently.
- Vertical scaling buys breathing room quickly: more CPU and memory can defer more complex architectural work while you understand your actual bottlenecks.
- Caching is the highest-leverage change, moving frequently read data into Redis or Memcached dramatically reduces query load.
Caching does, however, introduce a new class of problem: cache invalidation. In practice, users sometimes see stale data when the cache isn't updated correctly after a write. Caching is easy to implement; maintaining consistency is where systems genuinely become complex. The first time a user sees outdated data, you'll understand why this is considered one of the two hard problems in computer science.
Stage 4: High scale when reads dominate 50K+ users
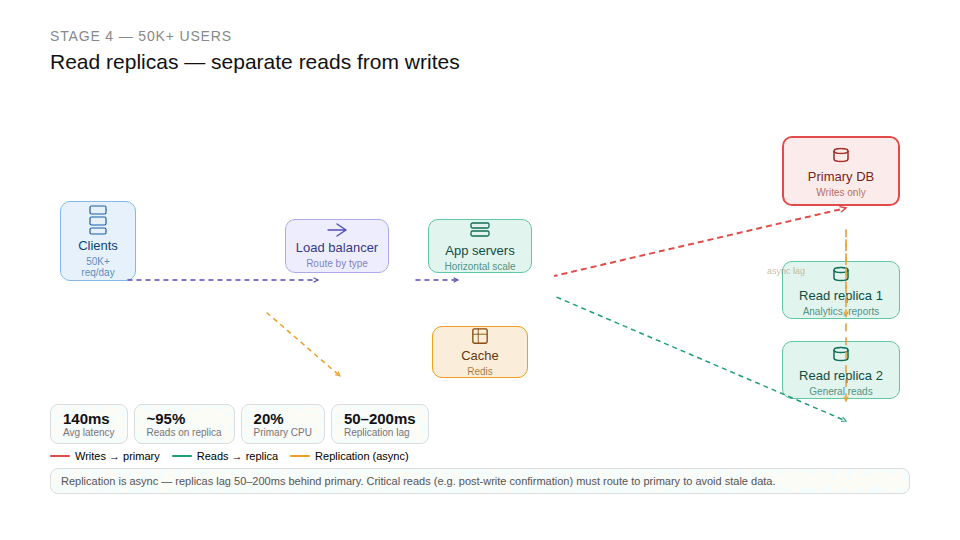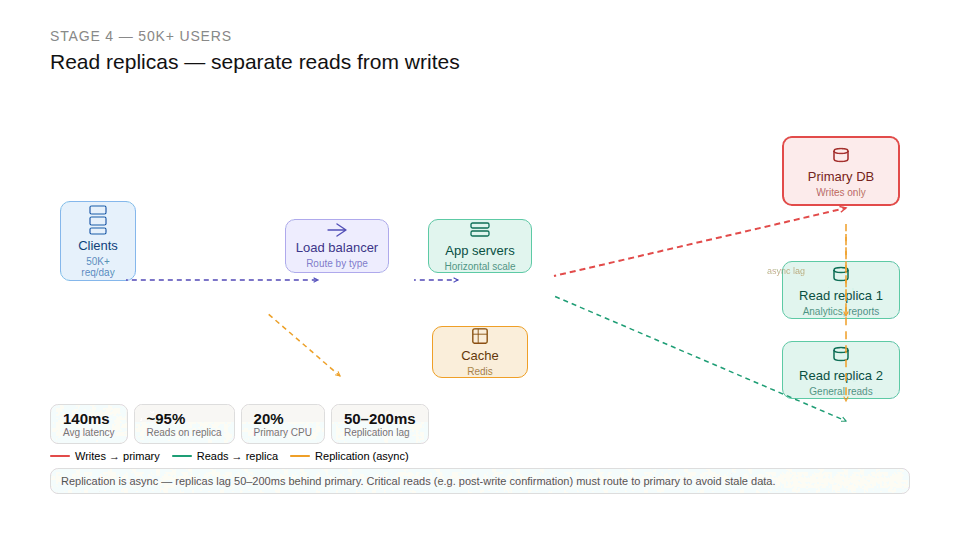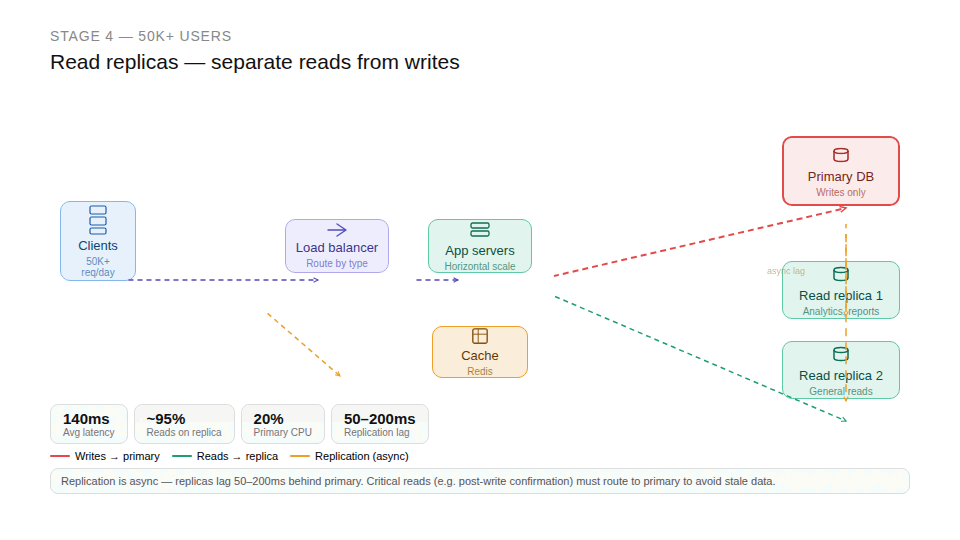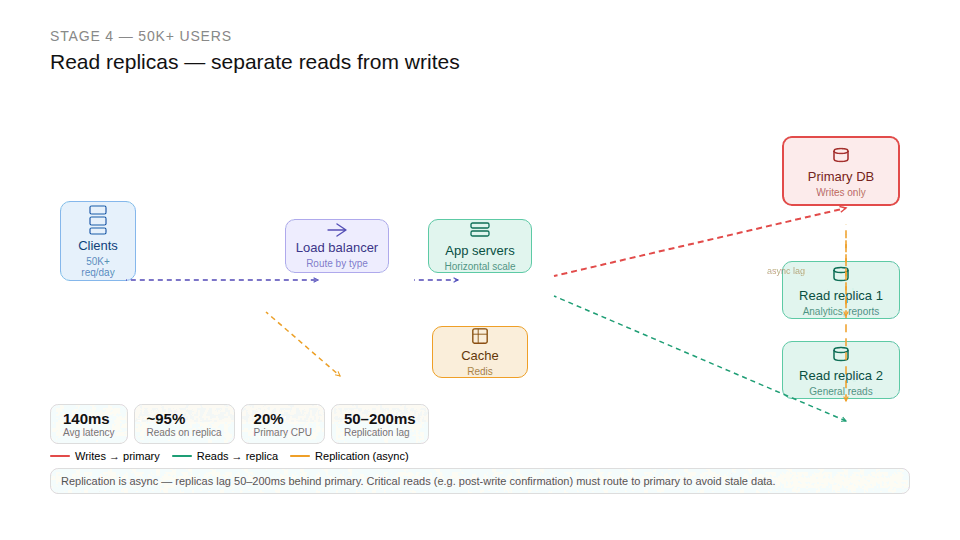
At higher scale, a new pattern emerges: read operations begin to overwhelm the system. Reporting, analytics, and data exports generate heavy queries that, if handled by the primary database, degrade the experience for everyone else. The signal to watch for is primary database CPU consistently above 80% even after caching — particularly driven by long-running analytical queries rather than transactional ones. The solution is read replicas. The primary database handles writes; replicas serve read-heavy operations. This separation protects the main workload from expensive queries and meaningfully improves performance across the board. Replicas come with their own trade-off, though: replication lag. Users sometimes don't see the latest data immediately. This requires routing critical reads like reading back a record you just created to the primary, while allowing eventual consistency for less time-sensitive operations like dashboards or reports. At high scale, consistency is no longer absolute it becomes a design decision you make deliberately for each use case.
FINAL THOUGHTS
Scaling is a continuous process, not a one-time decision. The most effective systems are not the most complex, but the ones that evolve gradually based on real demand. If you’re building a system today, focus on making it work well for your current users. You don’t need a perfect architecture you need one that can grow with you. If you’re already facing performance challenges, the solution is rarely adding more technology. It’s about understanding bottlenecks, making the right trade-offs, and scaling step by step. That’s where real-world experience makes the difference.